Tytuł projektu
Metody i narzędzia lingwistyki korpusowej
w badaniach bibliografii polskich wydawnictw zwartych
z lat 1997-2017
Metody i narzędzia lingwistyki korpusowej
w badaniach bibliografii polskich wydawnictw zwartych
z lat 1997-2017
Rodzaj, numer grantu i lata
NCN OPUS 12
2016/23/B/HS2/01323
2017–2020 (przedłużenie do 2021)
Wykonawcy
Prof. Adam Pawłowski (kierownik projektu),
dr Elżbieta Herden,
dr Piotr Malak (do 2018),
dr inż. Tomasz Walkowiak
Partner technologiczny
Konsorcjum CLARIN-PL
Cel
Celem proponowanych badań było stworzenie korpusu tytułów wydawnictw zwartych, opublikowanych w Polsce w latach 1997–2017, a następnie jego wieloaspektowa analiza informatologiczna i stylostatystyczna. Dane do badań zostały wygenerowane z zasobów bibliograficznych Biblioteki Narodowej, rejestrującej całość bieżącej produkcji wydawniczej w Polsce. Analiza bibliografii obejmowała następujące aspekty:
• wszechstronną analizę stylostatystyczną tytułów;
• automatyczną identyfikację płci autora;
• analizę rozkładu przestrzennego nazw miejscowych (miejsca wydań, nazwy geograficzne w tytułach);
• automatyczną klasyfikację gatunków piśmienniczych wyłącznie ma podstawie tytułów.
W badaniach wykorzystano m.in. metody taksonomii mikrotekstów. Wyniki automatycznej klasyfikacji gatunkowej weryfikowano przez porównanie ich z klasyfikatorami gatunku zapisanymi explicite w rekordzie. Większość wykorzystanych w projekcie narzędzi NLP (Natural Language Processing) opiera się na technice głębokiego uczenia, stosowanej masowo w różnych algorytmach sztucznej inteligencji.
Projekt obejmował następujące zadania:
1. Automatyczna klasyfikacja publikacji na podstawie tytułów (rozpoznanie dziedzin, rodzajów, gatunków i podgatunków piśmienniczych).
2. Porównanie klasyfikacji automatycznej z kategoryzacją opartą na metadanych, pochodzących z pól zawierających symbole klasyfikacji dziesiętnej (UKD) i hasła przedmiotowe BN (innymi słowy porównanie skuteczności działania opartego na wiedzy i intuicji człowieka z podejściem automatycznym).
3. Automatyczna detekcja płci autora dokumentów jednoautorskich wyłącznie na podstawie tytułu (weryfikacja w oparciu o faktyczną płeć autora).
4. Analiza statystyczna korpusu tytułów, obejmująca detekcję parametrów ilościowych (statystyki pozycyjne) i określenie rozkładu statystycznego zbioru.
5. Analiza rozkładu przestrzennego nazw miejscowych (toponimów) i nazw obiektów fizjograficznych (hydronimy, oronimy itd.), występujących w tytułach i (osobno) w metadanych.
Każda wielka bibliograficzna baza danych składa się z setek tysięcy, a nawet milionów rekordów, które zawierają pole miejsca wydania. Jeżeli udałoby się przypisać tym miejscom (miejscowościom) współrzędne geograficzne, możliwe byłoby rzutowanie bibliografii na mapę. Eksperyment taki przeprowadzono na bazie danych rekordów bibliograficznych, wygenerowanej z katalogu ogólnego Biblioteki Narodowej. Jego zawartość jest satysfakcjonująca w okresie istnienia państwa polskiego, czyli po roku 1918, ale niepełna przed tą datą. Państwo polskie jako suwerenny byt nie istniało do 1918 roku i żadna instytucja nie prowadziła wówczas systematycznej rejestracji wydawanych książek. Nawet jednak niepełne dane ukazują główne tendencje rozwojowe polskiego ruchu wydawniczego, a pośrednio szeroko rozumianej kultury polskiej.
Pierwszym etapem pracy było automatyczne rozpoznanie miejsc wydań zawartych w rekordach, przeprowadzenie ujednoznacznienia niektórych nazw i przypisanie im współrzędnych geograficznych oraz indeksów czasowych. Wykorzystano w tym celu niektóre narzędzia NLP, wytwarzane przez konsorcjum CLARIN-PL (analiza morfosyntaktyczna, rozpoznawanie nazw własnych). Etapem drugim było stworzenie dynamicznej wizualizacji setek tysięcy punktów, wyświetlanych na fragmencie mapy Europy widocznym na niewielkim ekranie komputera lub urządzenia mobilnego. Zadanie to można uznać za wzorcowy przykład humanistyki cyfrowej: obejmuje ono przetwarzanie wieloformatowych danych w otwartym dostępie (linked open data), uwzględnia wymiar czasowy, jest zaawansowane pod względem programistycznym, umożliwia wreszcie wartościowe poznawczo interpretacje (więcej na ten team w zakładce Kulturomika i wielkie bibliografie).
Poniższy odsyłacz uruchamia mapę satelitarną bibliografii,
przygotowaną przez zespół w składzie:
prof. Adam Pawłowski (lider i twórca koncepcji)
dr inż. Tomasz Walkowiak (programowanie)
dr Elżbieta Herden (analiza rekordów w formacie MARC)
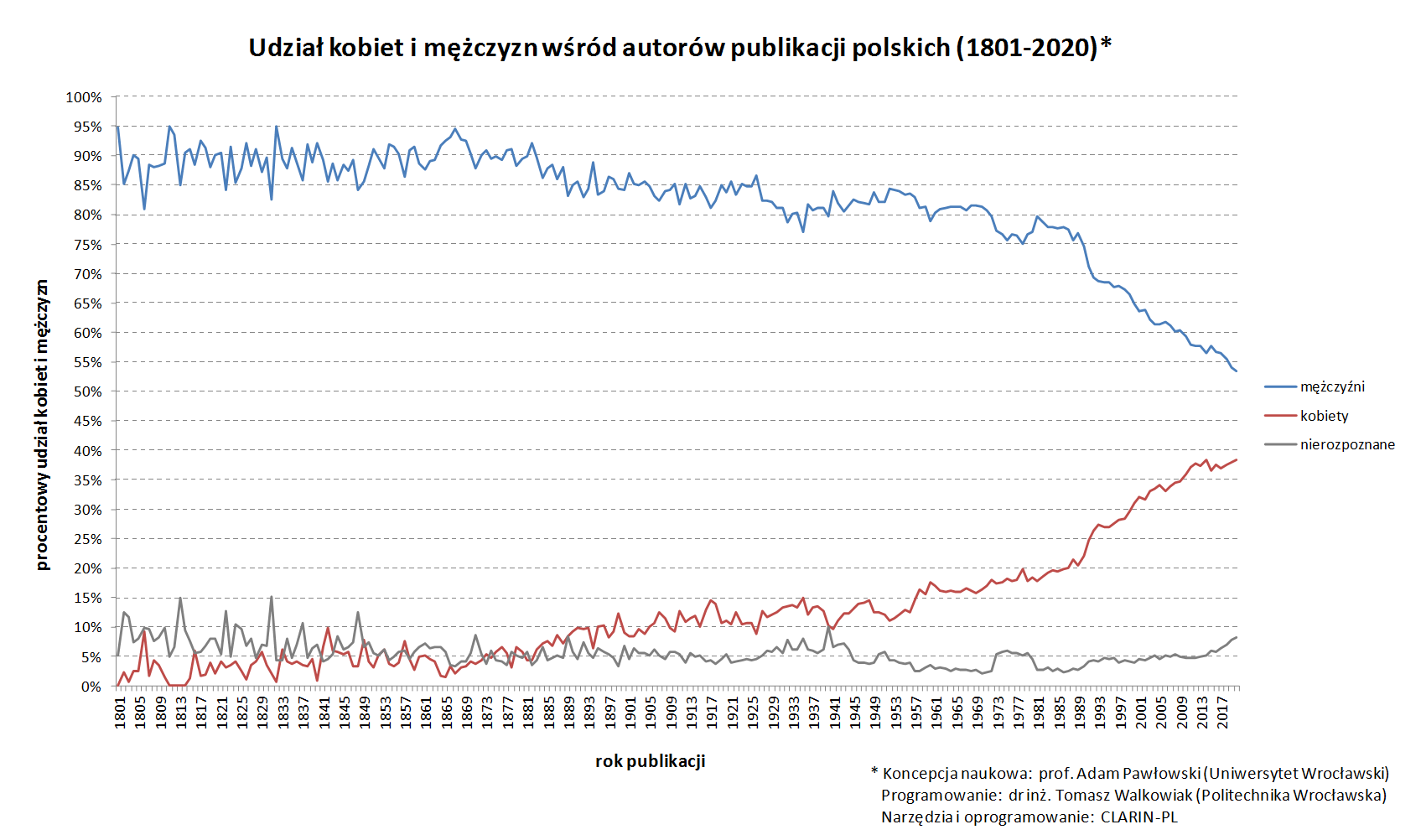
Skalę wieloletnich i głębokich procesów prowadzących do równouprawnienia płci ujawniają analizy wielkich zbiorów danych, które w sposób spójny i syntetyczny oddają sytuację w długich okresach (podejście określane w historiografii kwantytatywnej jako longue durée). Za przykład takich danych można bez nadmiernego ryzyka błędu uznać autorstwo książek. By stać się autorem monografii naukowej, podręcznika, poradnika czy dzieła literackiego, trzeba mieć wykształcenie i wiedzę, reprezentować wysoki poziom intelektualny, konieczna jest też powszechna akceptacja takiej roli społecznej konkretnej osoby lub grupy społecznej. Udział kobiet wśród autorów książek (‘publikacji zwartych’) jest więc bardzo dobrym miernikiem równouprawnienia płci i świadectwem sprawiedliwości społecznej w każdym miejscu i czasie.
Poniższy wykres wygenerowaliśmy na podstawie zawartości 1 264 295 rekordów bibliograficznych z lat 1801–2020, pochodzących z katalogu ogólnego Biblioteki Narodowej. Z uwagi na wolumen danych cała analiza została przeprowadzona automatycznie. Uwzględnialiśmy publikacje w języku polskim, odrzuciliśmy rekordy bez tytułów lub bez imienia (podstawowy wskaźnik płci) oraz te, które nie były opisami książek (np. sprawozdania konferencyjne). Zastosowaliśmy podział na 3 kategorie autorów: kobiety, mężczyźni i nierozpoznane. Wprawdzie liczby publikacji w poszczególnych latach nie były równe i nie zawsze reprezentowały cały strumień produkcji wydawniczej, uzyskany wynik jest przekonujący i nie należy się spodziewać, by pełne dane za wiek XIX zmieniły cokolwiek w przedstawionym niżej obrazie. Obecnie (2020) udziały autorów w grupie autorów książek rejestrowanych przez Bibliotekę Narodową wynoszą: mężczyźni (53,4% – 4 742 autorów), kobiety (38,4% – 3 415 autorek), osoby nierozpoznane (8,2%). Wzrost w stosunku do okresów wcześniejszych jest więc znaczący, a zarysowany tutaj „trend równouprawnienia” wydaje się trwały (więcej na ten temat w zakładce Kulturomika i wielkie bibliografie).
Badanie przeprowadził zespół w składzie:
prof. Adam Pawłowski (lider projektu i twórca koncepcji)
dr inż. Tomasz Walkowiak (programowanie)





The web page was designed with Mobirise